墻裂推薦 這款網絡排查工具,堪稱信息技術咨詢的神器

在當今高度依賴網絡的信息時代,無論是企業還是個人用戶,穩定高效的網絡連接都至關重要。網絡問題時常發生,從速度緩慢到連接中斷,這些問題不僅影響工作效率,還可能帶來經濟損失。作為一名信息技術咨詢服務從業者,我經常遇到客戶求助網絡故障排查。今天,我想向大家強烈推薦一款網絡排查工具,它憑借其強大功能和易用性,被廣泛認為是業界的神器。
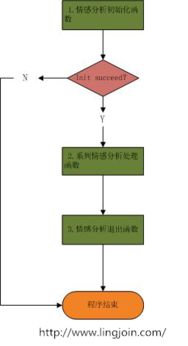
這款工具具備全面的診斷能力。它能夠快速掃描網絡拓撲,識別路由器、交換機等設備的運行狀態,并提供詳細的性能報告。通過實時監控網絡流量,它可以檢測到潛在瓶頸、丟包率異常或帶寬濫用問題。例如,在企業環境中,如果某個部門的網絡速度突然下降,這款工具能立即定位到問題源頭,可能是某個設備故障或惡意軟件占用資源。這大大縮短了故障響應時間,讓信息技術咨詢服務人員能夠迅速采取行動,減少業務中斷。
該工具的用戶界面設計直觀,即使是非技術人員也能輕松上手。它提供可視化圖表和警報系統,用戶只需點擊幾下,就能查看網絡健康度、延遲分析和安全威脅。信息技術咨詢服務中,我們常遇到客戶缺乏專業知識,而這款工具的自助診斷功能減輕了他們的負擔。同時,它支持跨平臺使用,包括Windows、macOS和移動設備,確保了靈活性和可訪問性。
這款工具在安全方面也表現出色。它可以檢測網絡入侵、未授權訪問和惡意活動,幫助用戶防范網絡攻擊。在信息技術咨詢服務中,安全問題往往是重中之重,這款工具不僅能排查故障,還能增強整體網絡安全防護。通過定期使用,用戶可以主動預防潛在風險,避免數據泄露或服務中斷。
實際案例中,我曾幫助一家中小企業使用這款工具解決頻繁的網絡斷線問題。通過工具的分析,我們發現是由于路由器固件過舊導致的不穩定。在升級后,網絡穩定性顯著提升,客戶的生產效率也隨之提高。這充分體現了該工具在信息技術咨詢服務中的價值——它不僅節省了時間和成本,還提升了客戶滿意度。
這款網絡排查工具是信息技術咨詢服務的得力助手。它集診斷、監控、安全于一體,適用于各種規模的組織。如果你正在尋找一款可靠的網絡問題解決方案,我強烈推薦嘗試它。相信我,一旦使用,你就會發現它如何簡化你的工作流程,讓網絡管理變得輕松高效。快去下載體驗吧,它絕對會成為你的日常必備神器!
如若轉載,請注明出處:http://m.fzdhc.cn/product/5.html
更新時間:2026-06-03 06:16:02